

In der Woche, vom 22. bis 26 Juni nahmen unsere Data Engineers Matthias Harder, Jiawei Cui und Michael Schaidnagel an dem Spark + AI Summit 2020 teil. Diese wurde von DataBricks der Firma hinter Apache Spark, aufgrund der aktuellen Lage erstmals vollständig online abgehalten. Spark ist ein Big Data Framework, dass es einem ermöglicht, große Datenmengen zu verarbeiten und auszuwerten. Die Konferenz bestand aus zwei Tagen Training und drei Tage voller interaktiver Sessions, Chat basierten Diskussionsgruppen und Technical Deep Dives von marktführenden Unternehmen im Bereich Big Data (Microsoft, Facebook, IBM). Für uns kombiniert die Konferenz zwei Bereiche, die zu unserem Kerngeschäft gehören: Big data und AI. Spark treibt nicht nur unseren hauseigenen DataLake an, sondern wird ebenfalls zur Datenaufbereitung für unsere Machine-Learning Modelle verwendet.
Die folgenden Neuigkeiten der Konferenz waren für uns besonders interessant:
Spark 3.0
Gleich zu Beginn der Konferenz wurde der Release von Spark 3.0 bekannt gegeben. Ein besonderes Highlight dieser neuen Version ist das Adaptive Query Execution Management (AQE). AQE kann während Laufzeit einer Query automatisch den Query Execution Plan anpassen und z.B. die Anzahl der Reducer anpassen. Dadurch verspricht DataBrix eine Leistungssteigerung beim Abfragen ohne händisches optimieren. Darüber hinaus optimiert AQE Join Operation von verschiedener Tabellen, was bisher eine Achilles Ferse von Spark war. Wir bei SmartDigtial erhoffen uns dadurch die Einsparung von einigen Datenaufbereitungsschritten in unseren Data Pipeline. Wir sind gespannt ob AQE zu einem Paradigmenwechsel in der Big Data Welt führt, welche bisher die Tendenz hatte, alle notwendigen Informationen denormalisiert in einer Tabelle zu haben, um teure Joins zu verhindern. In Zukunft könnten wir wieder vermehrt normalisierte Datenbank ähnliche Architekturen mit kleinen Fakten Tabellen sehen. Dies wird die Verbreitung von Spark sicherlich noch weiter beschleunigen. Zu den anderen Neuerungen bei Spark 3.0 zählen u.a. Dynamic Partition Pruning, beschleunigtes kompilieren von Abfragen und das Anzeigen von Optimierungshinweisen im Query Execution Plan.
Delta Lake
Data Lakes bestehen aus großen Mengen von Rohdaten, die in binärer Form wie z.B. Parquet files abgelegt sind. Das Anhängen neuer Daten ist für einen Data Lake kein Problem. Das Updaten von Daten führt jedoch dazu, dass diese Files neu geschrieben werden müssen. Das führt zu Problemen beim Zugriff. Darüber hinaus leiden viele Data Lake Projekte unter schlechter Ad-hoc query performance und dem sog. “too-many-small-files” Problem. Als Antwort darauf präsentiert Databrix den Delta Lake, der als strukturelle Schicht über die Parquet files gelegt wird. Diese Schicht garantiert, dass alle Datenbank Operationen ACID (Atomicity, Consistency, Isolation, Durability) gemäß ablaufen und ermöglicht somit eine direkte, konsistente Datenverarbeitung. Vereinfacht ausgedrückt: Wenn eine Operation einen Wert in einer Tabelle aktualisiert und eine andere Operation diesen Wert lesen will, muss die zweite Operation warten, bis die erste Operation die Aktualisierung abgeschlossen hat. In der Praxis wird dies durch die Speicherung zusätzlicher Metadaten und Versionen realisiert, die es auch ermöglich, auf ältere Versionen von Daten zuzugreifen.
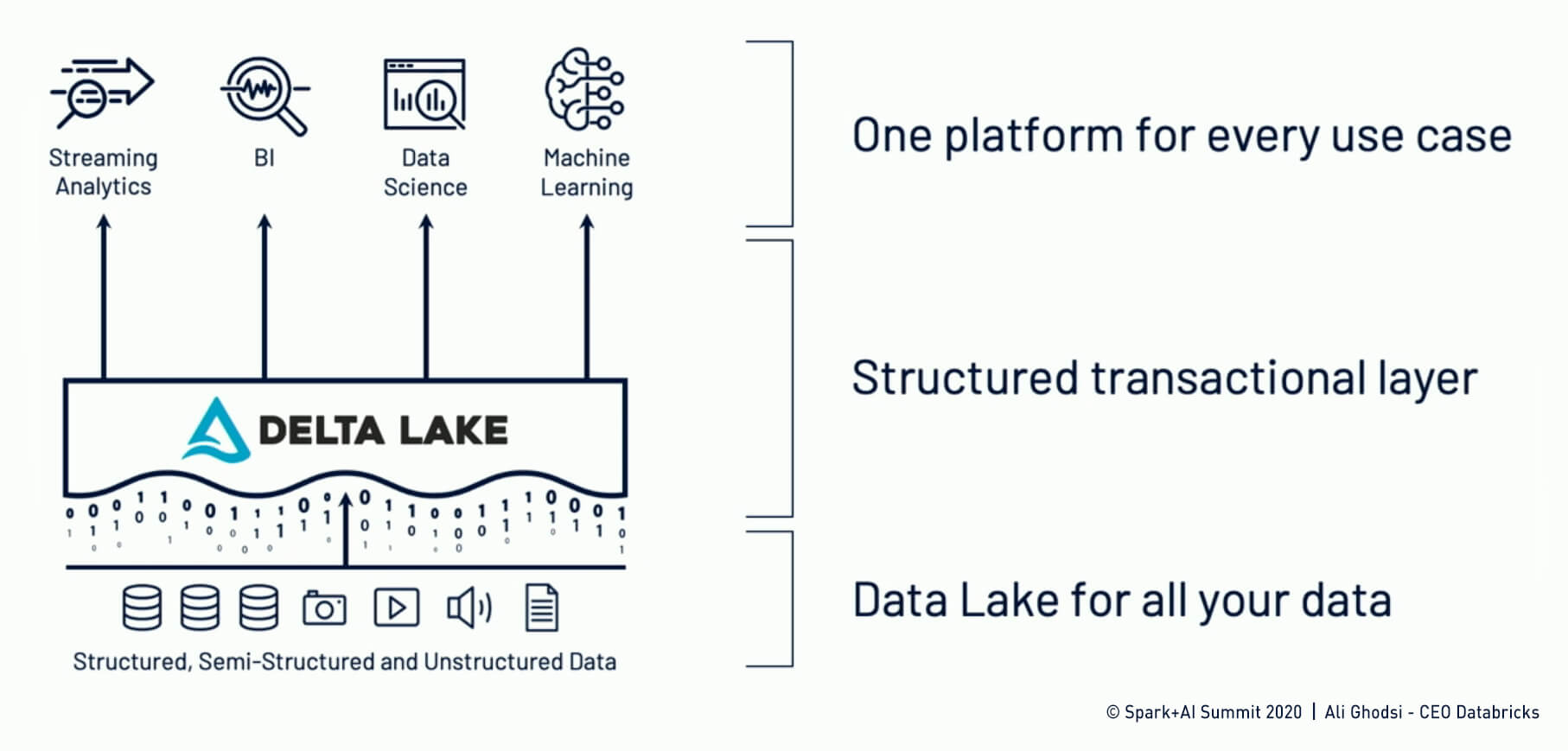 Ali Ghodsi – Intro to Lakehouse, Delta Lake
Ali Ghodsi – Intro to Lakehouse, Delta Lake
Entwicklungen im Bereich Data Science
Neben den Themen über Big Data war die Konferenz auch im Bereich Data Science für uns sehr interessant. Etwa 90% der aktuell vorhandenen Daten wurden in den letzten 2 Jahren generiert; das Datenwachstum ist und war in den letzten Jahren exponentiell. Die Entwicklung von Anwendungen die es Unternehmen ermöglichen, Daten abzurufen, zu verarbeiten, zu analysieren und dann in konkrete Lösungen umzusetzen, ist wichtiger denn je. Deshalb waren wir sehr erfreut die Fortschritte von Projekten wie ML flow und Kubeflow zu sehen. Beide Projekte steuern den kompletten Prozess von der Datenvorbereitung über das Modell-Training bis hin zum Deployment von hochleistungsfähigen Modellen. Die Konferenz half uns bei der Entscheidung, welche Technologie wir in Zukunft für unsere interne Data Science Workbench einsetzen möchten. Darüber hinaus waren die Trainings und die Sessions zum Thema Reinforcement Learning für uns sehr spannend, da wir in diesem ML Bereich mit das höchste Zukunftspotenzial sehen.
Alles in allem war die Konferenz außerordentlich bereichernd und lehrreich für unser Team, und wir freuen uns darauf, all die neuen Erkenntnisse und Funktionen in die Praxis umzusetzen!
Photo: Paul Smith | Unsplash